Summary
Procurement departments are investing heavily in digital tools, e-procurement[1] platforms and artificial intelligence solutions. Yet a significant blind spot persists in most organisations: procurement data quality. Without reliable, structured and complete data, no technology can deliver on its promise. This article is aimed at Chief Procurement Officers[2], purchasing managers and CIOs who wish to understand the real challenges of data in procurement, measure the impacts of poor data quality and activate pragmatic levers for lasting data structuration.
Contents
- Procurement data: from administrative constraint to strategic asset
- The hidden costs of poor data quality for the procurement function
- No effective artificial intelligence without clean procurement data
- How to guarantee structured and reliable procurement data over time
- Manutan, your partner for structuring indirect procurement data
Procurement departments are investing massively in their digital transformation. Yet a fundamental prerequisite is regularly underestimated: procurement data quality. High-performance tools built on incomplete, inconsistent or poorly structured data do not deliver the expected results. This gap between technological ambition and operational reality generates costly projects, biased decisions and a loss of confidence in the systems deployed. Understanding what procurement data quality really encompasses and why it conditions every digital transformation is the essential starting point of any modern procurement strategy.
Procurement data: from administrative constraint to strategic asset
Procurement data was long perceived as an administrative by-product: an accounting entry, a delivery note, a line in a spreadsheet. This view is now outdated. In a context of accelerating digital transformation, data has become a fully-fledged strategic asset, on a par with a supplier portfolio or an investment budget.
What is meant by procurement data quality? Reliability, completeness, structuration
What is procurement data quality, and why is it strategic? The answer comes down to three fundamental attributes.
Reliability means that data faithfully reflects reality: an up-to-date unit price, an active product reference, a verified supplier lead time. Completeness ensures that no critical field is missing: accounting code, order unit, country of origin. Consistency ensures that data is homogeneous across all systems whether the ERP, the e-procurement platform or the supplier management system.
In indirect procurement, these three attributes are often the hardest to maintain: references multiply, suppliers are numerous, and data entry processes remain fragmented. Poor data quality in this category has a direct impact on supply chain performance and the overall quality of procurement analytics.
Why is procurement data still under-exploited in most companies?
The causes of this under-exploitation are primarily organisational. Manual data entry introduces errors and inconsistencies at every stage of the procurement processes. Information systems coexist without being interconnected: ERP, procurement tools and accounting tools operate in different languages. The absence of dedicated governance leaves each user free to interpret data entry rules as they see fit.
The concept of Smart Data[3] (intelligent, structured and usable data) remains poorly embedded in the culture of procurement functions. Treating data as an asset to be managed rather than as a process by-product is a shift in mindset that few organisations have fully made. It is precisely this ability to transform raw data into a decision-making lever, what data intelligence encompasses, that today distinguishes the most mature procurement departments from those still submerged by their own information resources. This capacity to extract valuable insights from procurement data is the true mark of strategic procurement management.
The hidden costs of poor data quality for the procurement function
What does poor procurement data quality actually cost? The question deserves a precise answer. The impacts are not limited to visible errors: they accumulate silently within processes, supplier relationships and strategic decisions.
Order errors, supplier duplicates, invoice discrepancies: the true cost of poor data
An obsolete product reference in the system generates an erroneous order, a supplier return and an emergency replenishment. A poorly maintained supplier panel produces duplicates: two records for the same service provider, two payments for the same service. Undetected invoice discrepancies accumulate across dozens of order lines, with no one able to identify them rapidly.
Download our “Rationalise Your Supplier Portfolio” white paper.
The cost of manually processing these anomalies is considerable: operator time, supplier disputes and accounting audit risks. These costs remain invisible in standard dashboards, yet they weigh heavily on the real performance of the procurement function. A significant proportion of these expenditures is concealed within dark data, existing but unexploited data resources that harbour unsuspected savings within indirect procurement flows.
The "Garbage In, Garbage Out" principle applied to indirect procurement
The Garbage In, Garbage Out[4] principle is well known in computing. It applies with unerring precision to procurement: any spend analytics, any supplier reporting, any contract management or negotiation built on unreliable data produces erroneous decisions.
In indirect procurement, this phenomenon is amplified. Procurement data here is often the least structured of all procurement categories: a large number of suppliers, low standardisation of references and decentralised ordering processes. Consolidating indirect spend from heterogeneous data is like navigating without a map: the broad outlines appear visible, but the details that underpin decision-making remain in the dark.
No effective artificial intelligence without clean procurement data
Companies are investing in artificial intelligence tools to automate, predict and optimise supply chain operations. Yet a paradox emerges: these tools are deployed on unprepared data foundations, which undermines their performance from the very first weeks of use. Artificial intelligence does not create quality where none exists.
AI in procurement: spend analytics, anomaly detection, order automation
The use cases for artificial intelligence in the procurement function are numerous and concrete: automated spend analytics, invoice anomaly detection, alternative supplier recommendations and automation of recurring low-value orders.
Each of these use cases depends entirely on the quality of the input procurement data. An anomaly detection algorithm trained on inconsistent data mass-produces false positives or, worse, fails to detect genuine anomalies. A supplier recommendation engine fed by an incomplete panel directs procurement teams towards unqualified service providers. Artificial intelligence amplifies data in both its strengths and its weaknesses. The risk increases when employees adopt AI tools not governed by IT departments, a phenomenon now identified as Shadow AI, which further fragments the organisation’s data resources and escapes all governance.
Data quality: the true prerequisite before any technology investment
Why does artificial intelligence need high-quality data to function? Because it simply exploits, at scale and at speed, whatever the data transmits to it. Its power lies in its ability to identify patterns across large volumes, but this ability becomes a risk if those volumes consist of poorly structured procurement data.
Structuring, cleansing and governing procurement data before deploying an AI tool or advanced ERP is not an optional preliminary step. It is the true prerequisite of any lasting digital transformation in procurement. Organisations that skip this step invest in systems and technologies that cannot deliver their full potential. The importance of data quality cannot be overstated: it is the bedrock of reliable supply chain management and meaningful data analytics.
How to guarantee structured and reliable procurement data over time
Once the diagnosis is established, the question becomes operational: how to build reliable procurement data in the long term? Two levers complement one another: organisational data management governance and source-level structuration via technical tools.
Implementing procurement data governance: roles, processes, tools
Effective procurement data management and governance rests above all on clear organisational choices. The key steps are as follows:
- Appoint a procurement data owner[5], responsible for the reliability and consistency of the supplier panel;
- Define standardised, shared and documented data entry rules;
- Implement a validation and enrichment process for supplier management data;
- Choose systems capable of interconnecting existing platforms without creating new silos;
- Train procurement teams in data culture, in the same way as they are trained in operational processes.
Governance is above all a human issue, not merely a technical one. A data entry rule that is not understood will be bypassed. A validation process not supported by management will be ignored. The sustainability of procurement data quality is built through everyday behaviours. This requirement for rigour extends beyond the operational scope: a genuine data-driven CSR policy also relies on reliable, traceable procurement data to measure the supplier footprint and steer responsible procurement commitments.
Punch-out and e-procurement as levers for structuring data at source
The most effective method of guaranteeing reliable procurement data is to structure it at the point of creation. This is precisely what e-procurement solutions and Punch-out enable[6].
Punch-out directly connects the client’s procurement system (ERP, procure-to-pay[7] platform) to the supplier’s online catalogue. The result: orders are generated without manual data re-entry, with standardised references, up-to-date contractual pricing and consistent accounting codes. Procurement data is clean from the very outset, with no human intervention that could introduce an error. This source-level structuration is the foundation upon which all reliable downstream analytical exploitation rests including spend analytics and supply chain performance analysis.
Manutan, your partner for structuring indirect procurement data
Manutan has been supporting companies in structuring their indirect procurement flows for several decades. This support goes far beyond providing a catalogue: it extends to technical integration, data management and procurement performance monitoring.
“We are going to use data to show that one factory consumes in a certain way, whilst another comparable factory consumes differently. We benchmark: we take all the companies, for example in construction, we look at how they operate, and we can say: ‘This is how procurement is done in construction.’ We can then explain to the client: your behaviour is slightly different; you probably have gains to make in digitalisation, and in the arbitration between premium brands or not. Data is paramount for this type of procurement.”
Xavier Laurent, Director of Mergers and Acquisitions, Manutan, Smart @Work, December 2020.
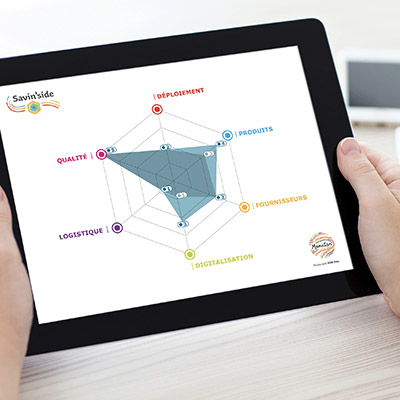
Savin’Side and Punch-out integration: how Manutan structures data from the point of order
Savin’Side is Manutan’s solution dedicated to indirect procurement management. It enables procurement departments to access reliable, structured data across their entire indirect spend: standardised references, consolidated contractual pricing and usable performance indicators.
The Punch-out integration with client procurement systems (ERP, procure-to-pay platforms) eliminates manual data entry and guarantees the consistency of order data at every transaction. From catalogue structuration to the exploitation of management data, this support covers the entire value chain of indirect procurement data quality.
Savin’Side and e-procurement integrations by Manutan:
Savin’Side and its Punch-out integrations are compatible with the leading ERP systems and procure-to-pay platforms on the market. This service is available in France, Belgium, Netherlands, United Kingdom, Germany, Italy, Spain, Sweden, Finland, Denmark, Norway, Poland, Czech Republic, Slovakia, Hungary, Portugal and Switzerland, at date of content publication.
[1] A dematerialised procurement process carried out via digital platforms
[2] Term denoting the procurement function in its entirety, from supplier strategy to order management
[3] Quality data, structured and contextualised, genuinely usable for decision-making
[4] Computing principle meaning that poor data quality as input produces unusable output results
[5] The person responsible for ensuring the quality, consistency and updating of a specific set of data within an organisation
[6] Integration protocol enabling a buyer to browse a supplier’s catalogue directly from their own procurement system, without manual re-entry